
ニューラルネットワークとは?
ニューラルネットワークはAIに利用される技術の一つであり、生物のニューロン(脳細胞)をモデル化したものです。以下の図のような構造を持ちます。

グラフの頂点が表すのはニューロンの細胞体であり、辺が表すのは軸索(神経細胞)です。これについて詳しく知る必要はありませんが、知っておくと理解が深まるでしょう。
ニューラルネットワークが行うのはとても単純なことです。左から右に信号を流すのです。ただ流しても意味がありませんから、頂点を渡るときに信号に抵抗を加えます。そして、頂点にわたってきた信号は増幅、又は減衰されます。最後の頂点(今回は右の頂点)すべてに信号が渡る時、最も信号が強い頂点を結果として返すのです。
画像認識を例としてみましょう。つまり、28×28のグレースケール画像に書かれた数字(0~9)を当てるAIを作ることを考えます。この時の構造は以下のようになります。
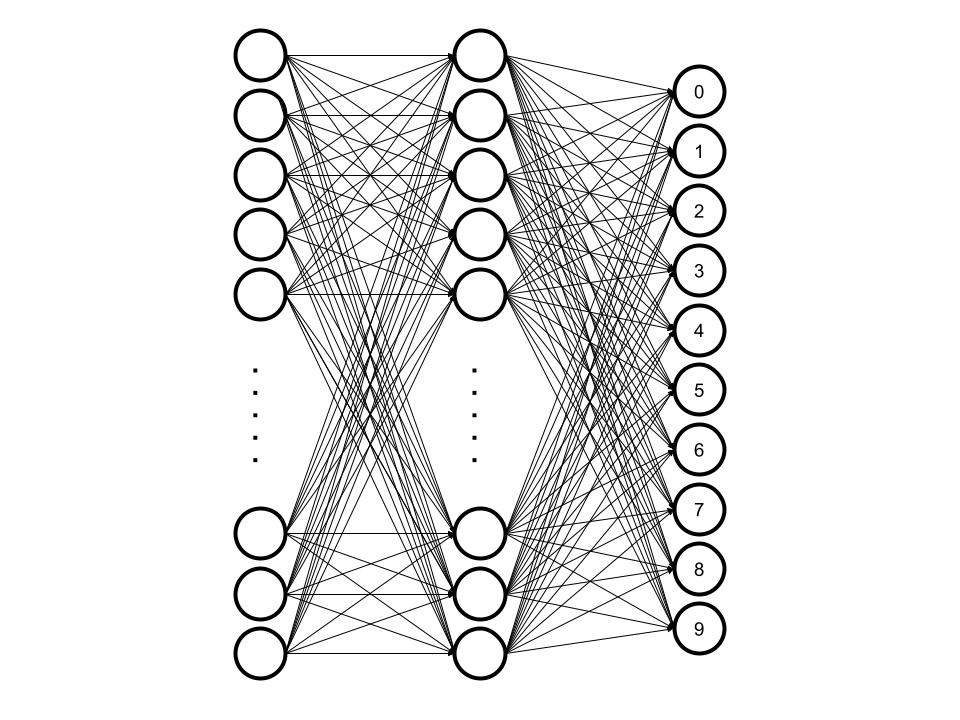
美しいような感じがしますね。それは置いといて、左の層(入力層)は28×28=784個の頂点で構成されています。そして、間の層(隠れ層)は100個の頂点、右の層(出力層)は10個の頂点から成ります。画像が与えられるとき、入力層へ1次元に引き伸ばされたピクセルデータが入力され、抵抗を加えられながら頂点間を伝い、頂点の信号は増幅、又は減衰され、出力層に達します。0~9に関連付けられた出力層の頂点の内、信号が最も強い頂点がAIの推論結果となります。
ここでの抵抗は、正確に「重み」と呼ばれます。また、頂点の信号をどれだけ増幅、又は減衰するのかを表す量は「バイアス」と呼ばれます。つまり、入力信号に重みをかけ、バイアスを加えながら信号を伝播させることでAIによる推論を可能にしているのです。
では、「重み」と「バイアス」は誰が、どうやって決めるのでしょうか?今回の例だと、「重み」は784×100+100×10=79400個も設定しなければなりません。一方で「バイアス」は110個で済みますが、合計79510個も設定しなければならないのです!これは人間が行えることではありません。そこで、それらのパラメータをコンピュータに自動で設定してもらうことにしたのです。このことを機械学習といいます。
結局のところ、ニューラルネットワークとは、ニューロンモデル上の機械学習です。今回の例では、3層から成る構造を利用しましたが、何層から構成されていてもかまいません(資源が許す限り)。特に多層のニューラルネットワークのことは、ディープラーニング(深層学習)と呼ばれます。
脳のシミュレーション
ニューラルネットワークは、ニューロンを模倣したアルゴリズムです。つまり、簡易的なニューロンのシミュレーションを行うのです。脳の特性を知りたいなら、シミュレーションを行えばよいのですから、ニューラルネットワークを用いて何か問題を解いてみましょう。先ほどと同様の画像認識を例とします。
プログラムはPythonで作成、実行します。モデルや与える訓練データを変更することで検証していきます。
検証対象となるモデルは6種類です。入力層と出力層は固定で、隠れ層のみを変更したものです。(’×’はノード間の全結合を表します)
- 100
- 500
- 2500
- 100×50×25
- 500×250×125
- 2500×1250×625
また、モデルに与える訓練データを3パターン用意します。
- 100%(60,000)
- 50%
- 25%
つまり、18通りの検証を行います。これらの検証には以下のコードが用いられます。Jupyter Notebook等で実際に実行し、検証してもかまいません。
import tensorflow as tf
import numpy as np
(train_img, train_label),(test_img,test_label) = tf.keras.datasets.mnist.load_data()
train_img, test_img = train_img / 255.0, test_img / 255.0
def model_predict(is_solid, cells, data_per):
if is_solid:
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28,28)),
tf.keras.layers.Dense(cells,activation='sigmoid'),
tf.keras.layers.Dense(10,activation='sigmoid')
])
else:
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28,28)),
tf.keras.layers.Dense(cells,activation='sigmoid'),
tf.keras.layers.Dense(cells / 2,activation='sigmoid'),
tf.keras.layers.Dense(cells / 4,activation='sigmoid'),
tf.keras.layers.Dense(10,activation='sigmoid')
])
model.compile(
optimizer='sgd',
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy']
)
space = 100 / data_per
filter = np.arange(train_img.shape[0]) % space == 0
history = model.fit(train_img[filter], train_label[filter], epochs=10)
loss, acc = model.evaluate(test_img, test_label)
return (acc, history.history['accuracy'])以上のプログラムを活用し、18通りの検証を行った結果は以下の通りです。
| ラベル | 検証正答率 | 成長率 | 訓練正答率 |
|---|---|---|---|
| 1-A | 91.4 | 21.1 | 90.9 |
| 1-B | 88.1 | 31.3 | 87.7 |
| 1-C | 85.4 | 40.1 | 85.2 |
| 2-A | 91.2 | 18.1 | 90.7 |
| 2-B | 88.2 | 27.8 | 87.9 |
| 2-C | 85.9 | 37.9 | 85.8 |
| 3-A | 90.7 | 22.4 | 90.5 |
| 3-B | 87.9 | 34.4 | 87.7 |
| 3-C | 86.1 | 46.6 | 85.6 |
| 4-A | 78.1 | 62.8 | 74.6 |
| 4-B | 55.0 | 38.2 | 49.4 |
| 4-C | 13.8 | 4.7 | 15.4 |
| 5-A | 85.4 | 71.0 | 84.4 |
| 5-B | 63.4 | 51.4 | 62.8 |
| 5-C | 46.6 | 24.5 | 35.8 |
| 6-A | 88.0 | 74.3 | 87.0 |
| 6-B | 73.1 | 60.2 | 71.1 |
| 6-C | 46.6 | 25.2 | 35.6 |
検証正答率:学習後モデルの検証データに対する正答率
成長率:学習初めと終りの訓練データに対する正答率の差
わかりにくいと思いますが一つずつ見ていきましょう。では、最初に1-Aモデルを見てみましょう。まとめると以下のようになっています。
- 検証正答率:91.4%
- 成長率:21.1%
- 訓練正答率:90.9%
これらについて考えてみます。まず、検証正答率が91.4%となっていることから、学習は適切なものだったと考えられます。また、成長率と訓練正答率を注目すると早い段階から訓練データに対する正答率が7割近くに達していることから、このモデルは手書き数字判定において優秀であると考えられます。
- 1-A
- 2-A
- 3-A
- 2-B
- 1-B
- 6-A
- 3-B
- 3-C
- 2-C
話は変わり、以上は検証正答率のランキングです。検証正答率の上位に位置するのは順に、1-A、2-A、3-Aとなっています。いずれも、訓練データを最も使用したモデルです。興味深いことに、ノード数が最も少ないモデルが最上位に位置しています。次に、4位以下を見るとここもまた、上位を1番と2番モデルが占めています。そして、やっと登場するのが最も複雑なノードを持つ6番モデルです。そして、6位に位置するこのモデルは訓練データ100%使用することで、この位置に立っています。これは当然でしょう。ここで考えられるのは「訓練データが十分に与えられているとき、単純なモデルのほうが優秀である」という仮説です。これについてさらに考えましょう。
- 1-A
- 2-A
- 3-A
- 6-A
- 5-A
- 4-A
以上は、100%訓練データを使用したモデルの正答率を比較したものです。1~3位において仮説は正しいようですが、4~6位においては正しくないようです。レイヤーが多いと、ノードも多くなった方が良いみたいです。
考察
人間は他の動物と比べて非常に多くのニューロンが脳内に存在します。また、それは複雑なネットワークを形成します。つまり、今回の実験の中では6番モデルにあたるはずです。このモデルについて表で眺めると、訓練データが多いモデルほど成長率が高くなり、正答率も高くなっていることに気づけます。
そうです。問題に正しく答えるためには多くの学習が必要なのです。しかし、この量には個人差があるでしょう。これについて考えるため、4番モデルと6番モデルを比べてみましょう。それぞれの検証正答率を比べると、同じ訓練データが与えられるているにも関わらず6番モデルの方が正答率が高く出ています。このことから、ニューロン(ノード)の数、又はネットワークの複雑さにより個人差が現れるのだと予測できます。
また、人間の脳細胞はある時にピークまで増殖し、その後海馬を除いて増える脳細胞は無いといわれています。老化によりボケが生じるのも表から理解できるでしょう。もともと6番モデルであったものが4番モデルに推移するのです。100%の訓練データを用いても検証正答率が10%も減少しています。25%の訓練データを用いて場合は、約33%も減少しています。このことから、頭を使い続ける(学習する)ことで老化の影響を抑えられそうだとわかります。
以上のことをまとめるとこういうことになるでしょう。
頭の良さはどれだけ脳を使用したかである
とても単純な結論ですね。
ボーっとしていてはいけません。
